CorText
Brain-language fusion enables interactive neural readout
Check out our Preprint!
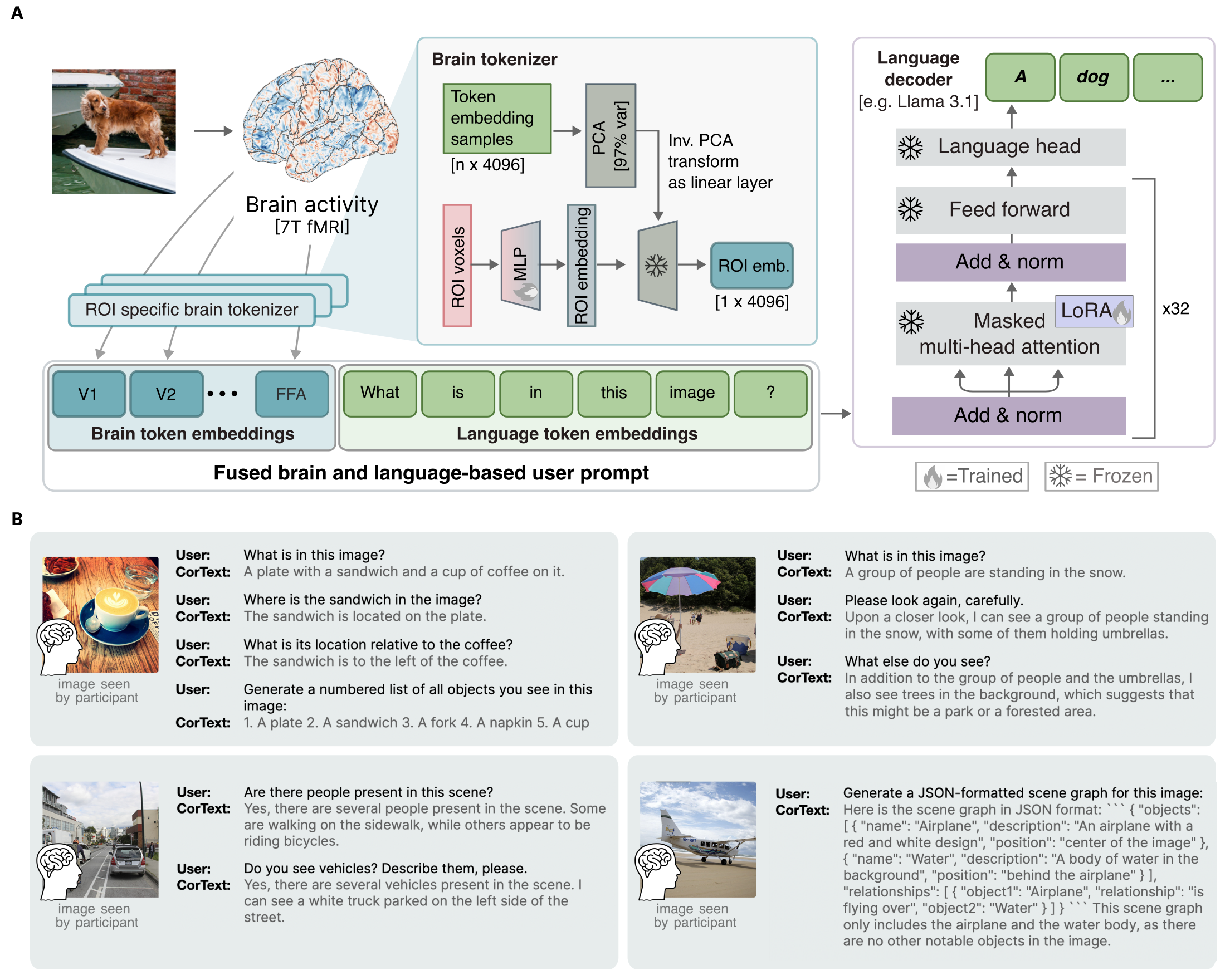
Large language models (LLMs) have revolutionized human-machine interaction, and have been extended by embedding diverse modalities such as images into a shared language space. Yet, neural decoding has remained constrained by static, non-interactive methods. We introduce CorText, a framework that integrates neural activity directly into the latent space of an LLM, enabling open-ended, natural language interaction with brain data. Trained on fMRI data recorded during viewing of natural scenes, CorText generates accurate image captions and can answer more detailed questions better than controls, while having access to neural data only. We showcase that CorText achieves zero-shot generalization beyond semantic categories seen during training. In-silico microstimulation experiments, which enable counterfactual prompts on brain activity, reveal a consistent, and graded mapping between brain-state and language output. These advances mark a shift from passive decoding toward generative, flexible interfaces between brain activity and language.
Further resources:
PDF of the short paper and poster presented at CCN 2025: pdf
PDF of the short paper presented at CCN 2024: pdf